
Update: The Kafka Native Add-on described in this post has since evolved into Kafkorama — a dedicated Streaming API Gateway for Apache Kafka, built on MigratoryData technology. This post is preserved for historical context.
MigratoryData is an ultra-scalable publish/subscribe WebSocket message broker that scales up to 10 millions concurrent WebSocket connections on a single 1U server (quite an important detail when looking at certain MQTT brokers which claim the same scalability number with vague language, often not mentioning the tens of virtual machines they use to achieve that number). For scaling out and ensuring ordering and delivery guarantees, MigratoryData comes with built-in active/active clustering by implementing concepts like replication, distributed in-memory caching, coordinators, gossip and probabilistic maps, sequence and epoch numbers as further detailed in a paper presented at the 18th ACM/IFIP/USENIX Middleware International Conference. In this blog post, we introduce an alternative approach to the MigratoryData built-in clustering—using Apache Kafka as a messaging backplane and a Kafka native add-on just released with MigratoryData 6.0.6—and discuss its application for an IoT use case.
Introducing the Kafka Native Add-on
Starting with version 6.0.6, MigratoryData includes a separately licensed Kafka native add-on which integrates MigratoryData and Apache Kafka seamlessly, with no coding required.
Messages flow bi-directionally and in realtime from MigratoryData to Kafka and vice-versa, using a simple
convention
for mapping between the MigratoryData subjects and the Kafka topics and keys. The first segment of a MigratoryData
subject corresponds to the Kafka topic, and the remaining segments of the MigratoryData subject correspond to the Kafka
key. If the MigratoryData subject consists of only of a single segment, then its corresponding Kafka key is null.
/vehicles/car66/speed, will be automatically forwarded to Kafka on the topic vehicles with
the message key car66/speed. On the other side, MigratoryData can be configured to listen
on a number of Kafka topics. Supposing the topic notifications is configured among these topics, a Kafka
message received on the topic notifications from a publisher with the message key car66 will be automatically
consumed by MigratoryData and forwarded in realtime to all devices subscribed to the subject /notifications/car66.
Enabling the Kafka Native Add-on
The Kafka native add-on is preinstalled in MigratoryData 6.0.6+, and the default evaluation license key
included with the installation packages can be used to evaluate it. To enable the
Kafka native add-on, configure the parameter ClusterEngine in the configuration file migratorydata.conf as follows:
ClusterEngine = kafka
Configure the parameter bootstrap.servers in the configuration files integrations/kafka/consumer.properties and
integrations/kafka/producer.properties with the list of Kafka node addresses where MigratoryData will connect for
Kafka cluster discovery. Finally, configure the parameter topics (or topics.regex) in the configuration file
integrations/kafka/consumer.properties and provide the list of Kafka topics (or a topic pattern) to be consumed by
MigratoryData from Kafka. Please refer to the
documentation for more details and more configuration options.
MigratoryData Built-in Clustering
The MigratoryData built-in clustering architecture is optimized for subscribers-dominated use cases and it scales out linearly with the number of subscribers. Because MigratoryData scales up efficiently, the MigratoryData clusters are typically small.
For example, a web app which displays realtime information such as live scores and odds—having more than one hundred million users and more than one million concurrent users—employs a MigratoryData cluster of ten nodes. When a score update occurs, a message is sent to one node of the MigratoryData cluster. Our built-in clustering algorithm forwards that message to the node which is the coordinator for the subject of that message. In turn, the coordinator assigns sequence and epoch numbers to that message and replicates it to the entire cluster. By utilizing this method, ordering and delivery are guaranteed. Ordering is guaranteed by the unique coordinator node for each subject (each node of the cluster is the coordinator for a distinct subset of all subjects), and delivery is guaranteed by the message replication to a memory cache of each node. Therefore, if a client reconnects to any node after a failure, it will obtain all messages from the last sequence and epoch numbers it previously received.
For the sports app above—which is a subscribers-dominated use case—the clustering architecture is efficient due to the size of the cluster being small and the rate of incoming messages being much lower than the rate of outgoing messages (with one million concurrent users connected, each incoming message is multiplexed into one million outgoing messages).
For publishers-dominated use cases, such as IoT where each device typically sends more information to the backend than it receives, the clustering architecture above could become inefficient due to the replication of each incoming message to the entire cluster. One way to solve this issue is to break the cluster into multiple smaller clusters, where each smaller cluster handles a distinct subset of devices. However, in order to avoid the partition of devices into multiple groups, a new and more efficient clustering architecture, using a Kafka backplane, is presented below.
Clustering Using a Kafka Backplane
In electronics, a backplane is a group of parallel connectors, where cards can be plugged in. We use this concept of backplane for implementing a new clustering architecture to connect multiple MigratoryData instances. We implement a backplane using Kafka where any number of MigratoryData instances can be plugged into the Kafka backplane using the Kafka native add-on.
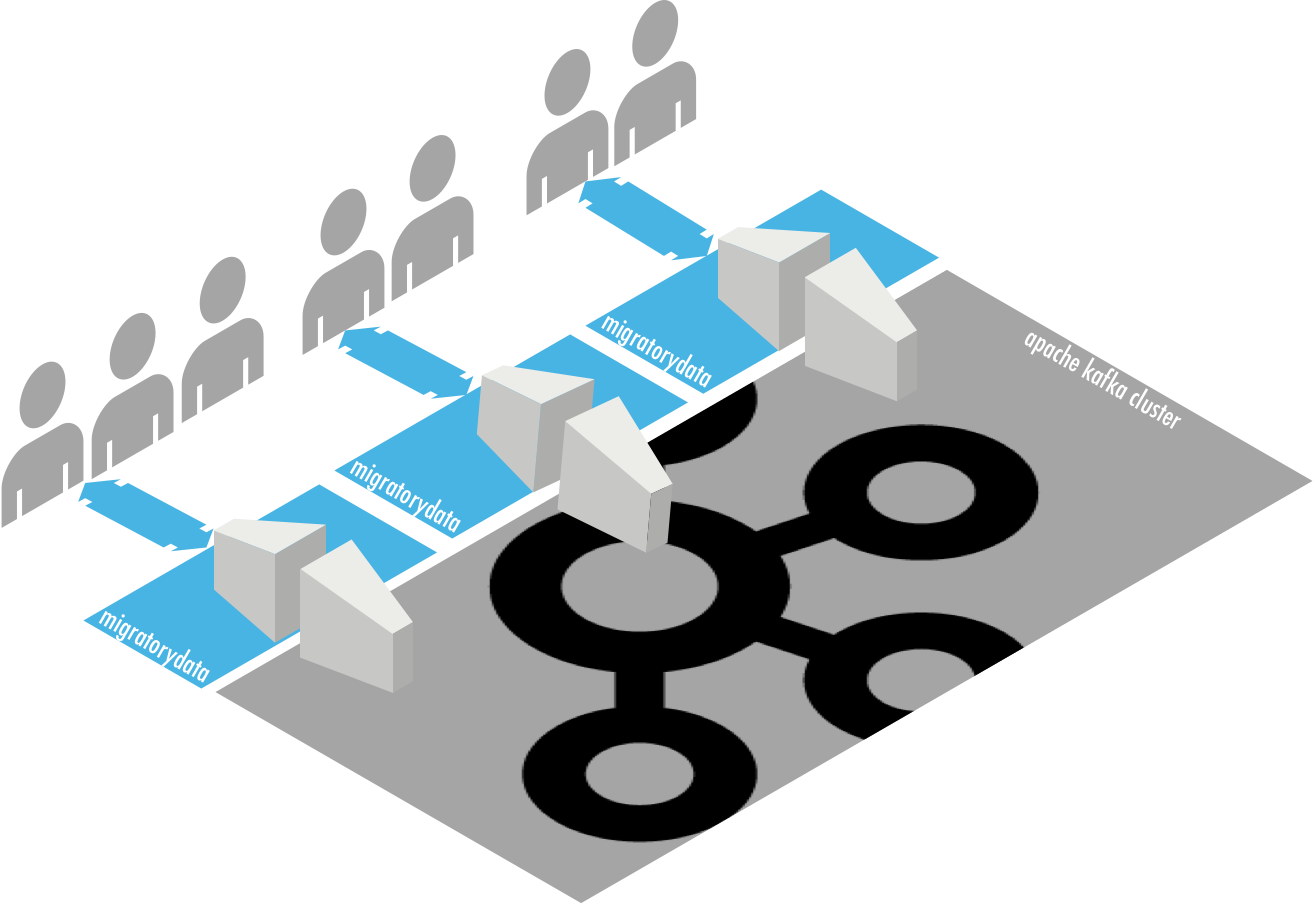
With this new clustering architecture, a message received by a MigratoryData node is automatically forwarded to the Kafka backplane to be persisted and consumed by various applications of the Kafka ecosystem, including MigratoryData, provided, however, that MigratoryData is configured to consume the topic of that message.
If we return to the IoT example above, where each connected vehicle sends the speed information to the backend on a
regular basis as messages with the subject /vehicles/car/speed, then it is sufficient for each MigratoryData node that
receives these messages to forward them to the Kafka backplane on the topic vehicles. Therefore, configuring MigratoryData
to consume the topic vehicles is not necessary. The new clustering architecture enables message injection into the
backend to be performed independently by each MigratoryData node, thus achieving an efficient linear MigratoryData
clustering scale-out.
Finally, if devices have to be updated with notifications from the backend, then each device car<X> should subscribe
to the subject /notifications/car<X>, and each MigratoryData should be configured to consume the Kafka topic
notifications. To notify the device car<X> from the backend, a Kafka message has to be published on the
topic notifications with the key car<X>. Each MigratoryData node will automatically consume this Kafka message, and
the car<X> device will receive in realtime the message from the node it is connected to. If a disconnection
occurs, then the device will still be able to obtain the message from the node it reconnects to as each node
receives the message from Kafka. Therefore, an indirect cluster replication still occurs, but it is limited only to the
topics configured by MigratoryData to be consumed from Kafka.
Conclusion
From a Kafka perspective, the native integration between MigratoryData and Kafka provides an off-the-shelf solution for extending Kafka messaging to millions of web, mobile, and IoT users. From a MigratoryData perspective, this integration is a gateway to the rich ecosystem of Kafka, which includes the most popular technologies, from durable storage to event stream processing.
Clustering with a Kafka backplane is immediately available by simply enabling the Kafka native add-on, with zero coding and no mapping to maintain between MigratoryData subjects and Kafka topics. The resulting cluster is stateless, and thus, ideal for easy deployments and autoscaling using cloud technologies such as Kubernetes. Ultimately, clustering with the Kafka backplane enables new realtime messaging applications with millions of users, both for subscribers-dominated and publishers-dominated use cases.
Clustering with a Kafka backplane, however, comes with a cost in comparison to the MigratoryData built-in clustering. An additional Kafka service has to be deployed and maintained, unless you use a fully managed Kafka service from one of the existing providers like Azure Event Hubs or Confluent.
In the tutorial MigratoryData with an Azure Event Hubs backplane, we provide detailed instructions on how to use the fully managed Kafka-compatible service provided by Azure Event Hubs as a backplane for MigratoryData, while running MigratoryData on Azure Kubernetes Service (AKS). Integration with Confluent will be detailed in a future article.