
Integrating Apache Kafka with millions of Internet facing devices is challenging. Typically used to interconnect backend systems, Kafka needs to delegate its messaging over the Internet to another service. WebSockets is the modern standard for implementing realtime messaging over the Internet. In this article, we discuss how to scale a WebSockets service to extend Kafka messaging to and from millions of connected devices. We also show how an Application Delivery Controller (ADC), such as F5 BIG-IP or Citrix ADC, can be used to accelerate Kafka messaging across the Internet.
Kafka Messaging over WebSockets
A number of WebSockets-based realtime technologies, including certain MQTT brokers, provide integration with Kafka either natively using the Kafka API, or by means of some Kafka connectors deployed within an intermediary Kafka Connect service. Some of these technologies rely on Kafka to handle various messaging aspects such as topic subscriptions and delivery message status.
One of these WebSockets-based realtime technologies is MigratoryData, which provides native integration with Kafka. MigratoryData implements advanced messaging features such as active/active clustering, message replication, distributed in-memory caching, and sequence and epoch number management to achieve message delivery, message ordering, and message recovery after failures in realtime, all without the need to query Kafka, and therefore without adding latency to message delivery and overhead to Kafka.
Scaling WebSockets
A vertically scalable WebSockets technology means a software which can efficiently use the entire capacity of a single machine. As a corollary, the messaging capacity of a vertically scalable WebSockets technology increases in terms of number of clients and volume of messages by adding more resources to that machine, such as CPU, memory, and network.
A WebSockets technology scales horizontally if it implements some clustering techniques to deploy it on multiple machines and be seen by the clients as a single entity. In addition, if the messaging capacity of the WebSockets technology increases proportionally as new machines are added to the cluster, then we talk about an efficient form of horizontal scalability named linear horizontal scalability.
MigratoryData is an example of a vertically scalable WebSockets technology which scales horizontally in a linear manner. Indeed, running on a single machine with 2 x Intel Xeon X5650 CPU and 96 GB RAM, MigratoryData has been benchmarked to scale vertically up to 10 million concurrent WebSockets clients, with a message capacity of 0.8 Gigabit per second. Also, when integrated natively with Kafka, MigratoryData scales horizontally in a linear manner, as its cluster members are independent of each other, with no state shared across the MigratoryData cluster.
Horizontal scalability is important because deploying a WebSockets technology on multiple machines is a condition to achieve fault tolerance and high availability of a WebSockets service. However, vertical scalability is the key to efficiently scale a WebSockets service to millions of devices. For example, handling the realtime WebSockets messaging of a web application having 100 million users with a cluster of ten machines rather than one thousand machines is far more than marginal, given the cost and complexity to manage a large number of machines and licenses.
While vertical scaling is specific to each WebSockets implementation, horizontal scaling is typically implemented by splitting the clients between all cluster members by using a load balancing approach.
For example, to vertically scale WebSockets, MigratoryData employs a number of workgroups to process the WebSockets clients in parallel. A WebSocket client is assigned to a workgroup according to a hash on its IP address as further explained in the following architecture paper.
Below we discuss various load balancing approaches for horizontally scaling WebSockets.
Load Balancing using API
One possibility for horizontal scaling is to implement load balancing at the client side. In order to connect a client to the WebSockets cluster, the client API library selects randomly one WebSockets server of the cluster from a list of server URLs encoded into the application. In order to allow for heterogeneous deployments, this list of server URLs may be accompanied by a weight for each server, allowing to bias the selection.
This simple mechanism using a hard-coded list of servers at the client side works well for many deployments of MigratoryData. Being ultra-scalable, MigratoryData is deployed in clusters with a relatively small number of servers. In this way, it is feasible to specify the list of server URLs in the application. Moreover, when used for realtime web applications, users download the access logic prior to connecting. This relieves the need to update the list of servers in the application when a server is removed or added to the list. Finally, MigratoryData implements a quick reconnect technique which automatically and immediately selects another server in the list, if the connection to a server in the list fails.
Load Balancing using DNS
Another simple load balancing mechanism is using DNS. It consists of configuring a single DNS domain name such as
push.example.com to be mapped to the IP addresses of the machines of the WebSockets cluster. In this way, all clients will use a
unique DNS domain name to connect to the cluster. The API client library will query the DNS service to get the IP address
where to connect to. The DNS service will resolve the domain name according to an algorithm such as round robin.
As with the previous load balancing method using API, if a server of the WebSockets cluster goes down or is stopped for maintenance, the DNS service will continue to resolve the domain name to the IP address of that cluster member.
Whether in the previous load balancing method using API, quickly reconnecting to a new server minimized the impact when a server is down, things are more complex with DNS load balancing.
The main issue with DNS is that resolving addresses is typically cached during a certain period of time (TTL) at various levels, from the local operating system and running environment (e.g. JVM) to the intermediary DNS servers. In addition, applications typically resolve to the first IP address of the list of IP addresses resolved by the DNS service. This makes sense in most cases as the list of the IP addresses returned by the DNS is in a random order, unless when it is cached. If cached, an application might resolve during the TTL to the same IP address, which might correspond to a failed server in the cluster.
Therefore, to avoid the DNS caching issue, the client API library of the WebSockets technology has to use the entire list of IP addresses rather than the first entry, and resolve the domain name to a random IP address of this list.
Avoiding the DNS caching issue is implemented for example by the MigratoryData client API for Node.js using the method setDnsOptions.
Load Balancing using ADC
Finally, load balancing using an Application Delivery Controller (ADC) is discussed. This mechanism uses a hardware or software (on-premises or on the cloud) ADC, such as F5 BIG-IP or Citrix ADC, to balance clients to the servers of the WebSockets cluster. The diagram below shows how a client establishes a bidirectional communication with Apache Kafka through F5 BIG-IP and the WebSockets cluster:
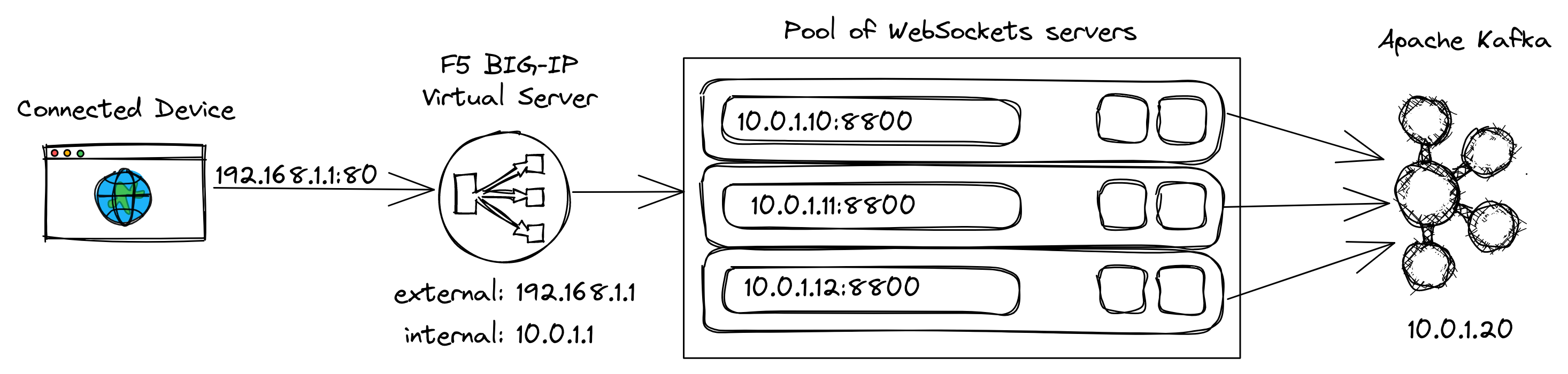
As with the DNS load balancing, the clients use a single address to connect, which is the external, public IP address or its domain name of a virtual server configured by F5 BIG-IP. The TCP connection of a client is terminated by the virtual server, which opens a new TCP connection on the internal network to a WebSockets server of the pool of servers assigned to the virtual server. The WebSockets server is selected from the pool according to an algorithm defined by that pool, such as round robin. F5 BIG-IP permanently monitors the health of the pool members. Hence, F5 BIG-IP will attempt to always select a healthy WebSockets server for any client connection.
This load balancing method has other advantages besides the improved load balancing discussed above. ADC can be used for firewall, DDOS protection, or TLS/SSL offloading. Since clients connect in a fist phase to the ADC, the ADC can be used to encrypt and decrypt the traffic, freeing up the WebSockets servers for other tasks or allowing the use of cheaper machines for the WebSockets servers. This cost saving is however eroded by the cost of maintaining an ADC infrastructure, which is not incurred when using API or DNS load balancing.
One potential issue with the ADC is when your WebSockets technology relies on the IP address of the client to assign
the client to a workgroup of the WebSockets server, like MigratoryData does. In this setup, all clients of a WebSockets server will
come from the same IP address, which is the internal address of the ADC. To handle this problem, MigratoryData introduced
a parameter X.ConnectionOffload which should be set on true in order to assign a client to a workgroup not only based
on the source IP address but also by the source port of the client. In this way, even if the IP address remains unchanged,
the source port is always different and the clients can be balanced across the workgroups of the WebSockets server.
Final thoughts
Hopefully, this article will help you understand some key aspects in extending and scaling Apache Kafka across the Internet to millions of connected devices using WebSockets such as:
- the importance of handling as much as possible of the messaging aspects in the WebSockets service to not add overhead to Kafka and to achieve message delivery and recovery in realtime
- the importance of the vertical scalability of your WebSockets technology
- the various load balancing ways to achieve horizontal scalability, including acceleration with F5 BIG-IP or Citrix ADC
You will have to address these aspects if you plan to build such a WebSockets service. At MigratoryData, these aspects have been addressed during the evolution of the MigratoryData technology over the last decade.
Please let us know if you need more details on this topic or download MigratoryData and evaluate it for free.